Cross-Entropy
Cross는 말그대로 p(x)와 q(x)가 서로 교차해서 곱한다는 의미이다.
Entropy값이 정보를 최적으로 인코딩하기 위한 필요한 bit라면
Cross-Entropy는 틀릴 수 있는 정보 양을 고려한 최적으로 인코딩할 수 있게 해주는 정보량으로 볼 수 있다.
주로 Regression에서는 최소자승법(MSE)이 cost function으로 쓰이고
Classification에서는 Cross-Entropy가 쓰이며
여러 class를 분류하는 Softmax에서 cost function으로 쓰이곤 한다.
공식
Cross-Entropy = P(X)*-log(Q(X))
P(X) : Target, Q(X) : Prediction
1) Target과 Prediction이 다를 때 2) Target과 Prediction이 같을 때
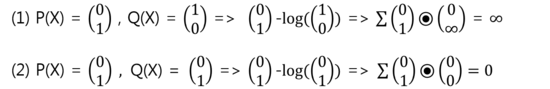
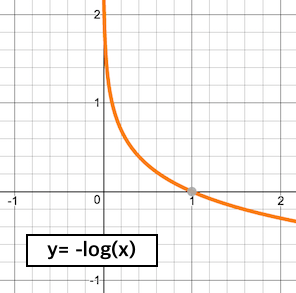
Cross-Entropy 값은 실제값과 예측값이 맞았을 경우에는 0으로 수렴하며
값이 틀릴경우 무한대로 발산하기 때문에
예측값과 실제값이 같도록
Cross-Entropy를 loss function으로 둔다.